{kind=link}
Esse é um ponto importante para entender. Às vezes, usar o método errado não apenas faz com que as páginas não sejam removidas do índice como pretendido, mas também pode ter um efeito negativo no SEO.
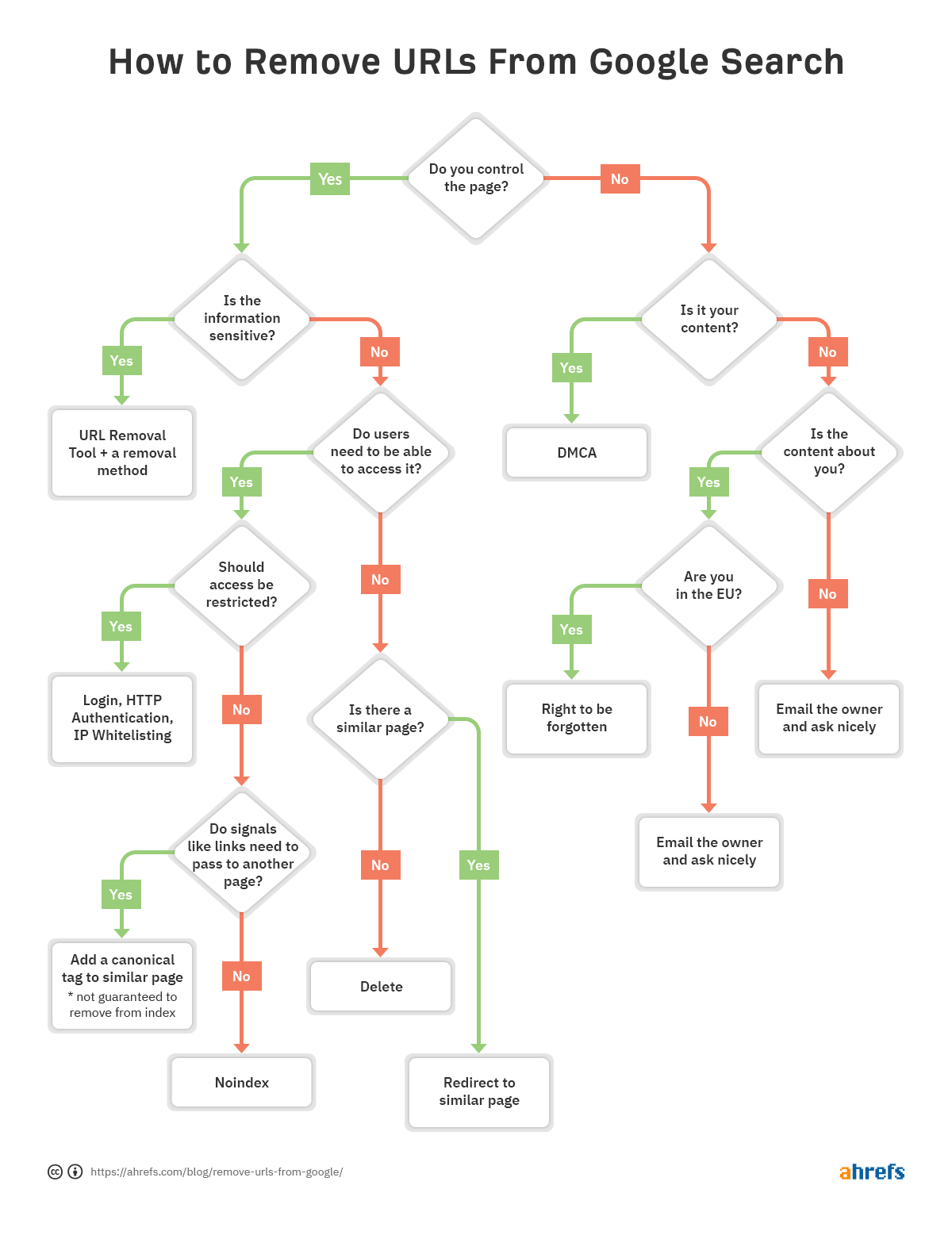
Para ajudá-lo a decidir rapidamente qual método de remoção é melhor para você, criamos um fluxograma para que você possa pular para a seção relevante do artigo.
Neste post, você aprenderá:
- Como verificar se uma URL está indexada
- Cinco maneiras de remover URLs do Google
- Como priorizar remoções
- Erros comuns de remoção a serem evitados
- Como remover conteúdo que não está em seu site
- Como remover imagens

O que normalmente vejo os SEOs fazerem para verificar se o conteúdo está indexado é usar um site: pesquisar no Google (por exemplo, site:https://ahrefs.com). Enquanto site: as pesquisas podem ser úteis para identificar as páginas ou seções de um site que podem ser problemáticas se aparecerem nos resultados da pesquisa, você deve ter cuidado porque não são consultas normais e não informam se uma página é indexado. Eles podem mostrar páginas que são conhecidas pelo Google, mas isso não significa que sejam elegíveis para exibição em resultados de pesquisa normais sem o site: operador.
Por exemplo, site: as pesquisas ainda podem mostrar páginas que redirecionam ou são canonizadas para outra página. Quando você solicita um site específico, o Google pode mostrar uma página desse domínio com conteúdo, título e descrição de outro domínio. Tomemos, por exemplo, moz.com, que costumava ser seomoz.org. Qualquer consulta regular do usuário que leve a páginas no moz.com mostrará moz.com nas SERPs , enquanto site:seomoz.org mostrará seomoz.org nos resultados da pesquisa, conforme mostrado abaixo.
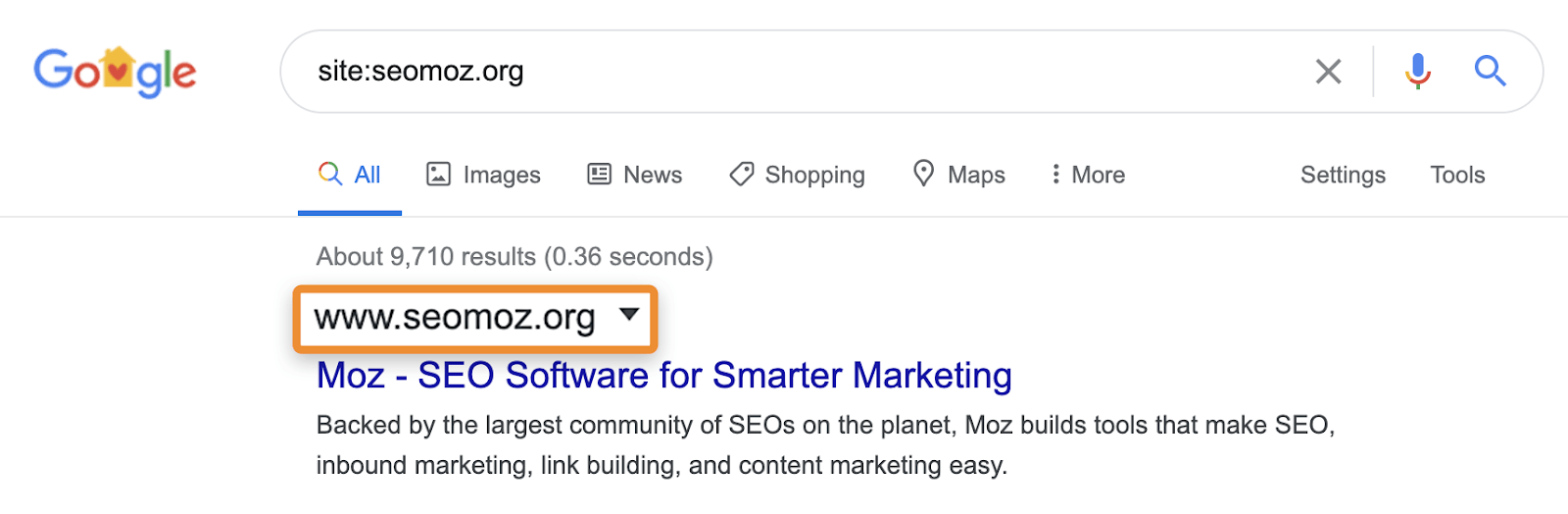
A razão pela qual essa é uma distinção importante é que ela pode levar os SEOs a cometerem erros, como bloquear ou remover ativamente URLs do índice do domínio antigo, o que impede a consolidação de sinais como PageRank . Já vi muitos casos com migrações de domínio em que as pessoas acham que cometeram um erro durante a migração porque essas páginas ainda aparecem para pesquisas de site:dominio-antigo.com e acabam prejudicando ativamente o site ao tentar “consertar” o problema.
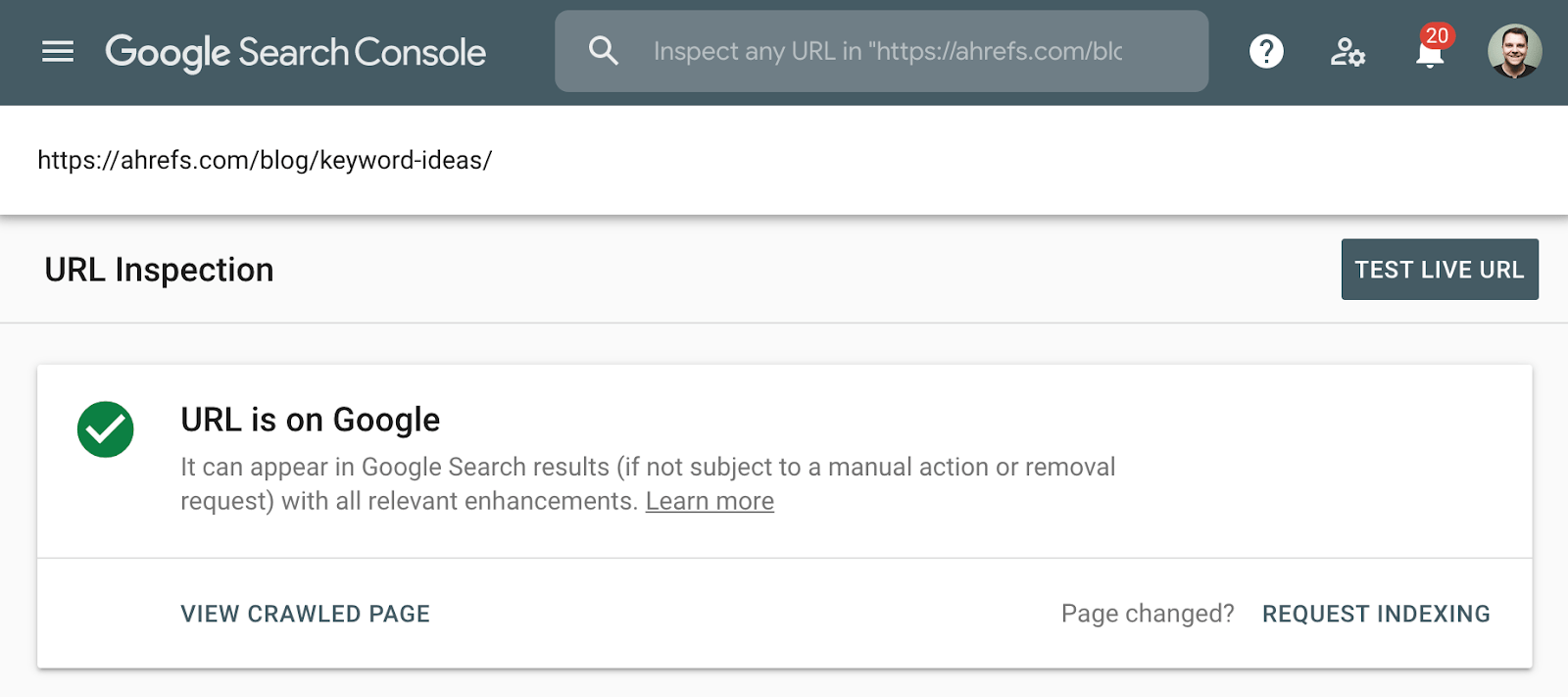
O melhor método para verificar a indexação é usar o relatório de cobertura do índice no Google Search Console ou a ferramenta de inspeção de URL para um URL individual. Essas ferramentas informam se uma página está indexada e fornecem informações adicionais sobre como o Google está tratando a página. Se você não tiver acesso a isso, basta pesquisar no Google o URL completo da sua página.
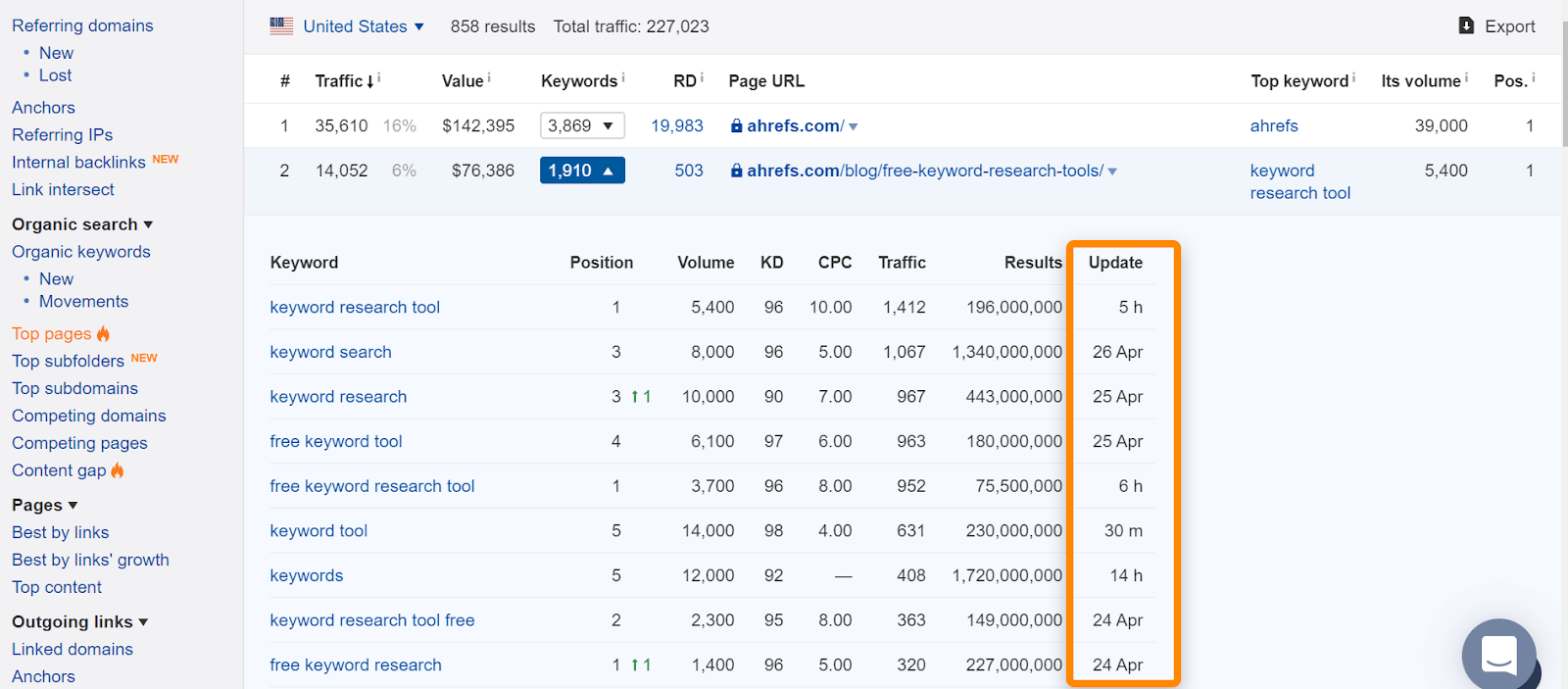
No Ahrefs, se você encontrar a página em nosso relatório “Principais páginas” ou classificação para palavras-chave orgânicas, isso geralmente significa que a vimos classificada para consultas de pesquisa normais e é uma boa indicação de que a página foi indexada. Observe que as páginas foram indexadas quando as vimos, mas isso pode ter mudado. Verifique a data em que vimos a página pela última vez para uma consulta.
Se houver um problema com uma URL específica e for necessário removê-la do índice, siga o fluxograma no início do artigo para encontrar a opção de remoção correta e vá para a seção apropriada abaixo.
Se você remover a página e exibir um código de status 404 (não encontrado) ou 410 (desaparecido), a página será removida do índice logo após ser rastreada novamente. Até que seja removida, a página ainda pode aparecer nos resultados da pesquisa. E mesmo que a própria página não esteja mais disponível, uma versão em cache da página pode estar temporariamente disponível.
Quando você pode precisar de uma opção diferente:
- Preciso de uma remoção mais imediata. Consulte a seção da ferramenta de remoção de URL.
- Eu preciso consolidar sinais como links. Consulte a seção de canonização.
- Preciso da página disponível para os usuários. Veja se as seções noindex ou de restrição de acesso se encaixam na sua situação.
Opção de remoção 2: Noindex
Uma tag meta robots noindex ou uma resposta de cabeçalho x-robots dirá aos mecanismos de pesquisa para remover uma página do índice. A tag meta robots funciona para páginas em que a resposta x-robots funciona para páginas e tipos de arquivos adicionais, como PDFs. Para que essas tags sejam vistas, um mecanismo de pesquisa precisa ser capaz de rastrear as páginas. Portanto, verifique se elas não estão bloqueadas no robots.txt . Além disso, observe que a remoção de páginas do índice pode impedir a consolidação de links e outros sinais.
Exemplo de um meta robots noindex:
<meta name="robots" content="noindex">
Exemplo de tag x-robots noindex na resposta do cabeçalho:
HTTP/1.1 200 OK X-Robots-Tag: noindex
Quando você pode precisar de uma opção diferente:
- Não quero que os usuários acessem essas páginas. Consulte a seção de restrição de acesso.
- Eu preciso consolidar sinais como links. Consulte a seção de canonização.
Opção de remoção 3: restrição de acesso
Se você deseja que a página seja acessível a alguns usuários, mas não aos mecanismos de pesquisa, provavelmente deseja uma destas três opções:
- algum tipo de sistema de login;
- Autenticação HTTP (onde é necessária uma senha para acesso);
- IP Whitelisting (que permite apenas endereços IP específicos para acessar as páginas)
Esse tipo de configuração é melhor para coisas como redes internas, conteúdo somente para membros ou para sites de teste, teste ou desenvolvimento. Ele permite que um grupo de usuários acesse a página, mas os mecanismos de pesquisa não poderão acessá-los e não indexarão as páginas.
Quando você pode precisar de uma opção diferente:
- Preciso de uma remoção mais imediata. Consulte a seção da ferramenta de remoção de URL. Nesse caso específico, você pode querer uma remoção mais imediata se o conteúdo que está tentando ocultar tiver sido armazenado em cache e precisar impedir que os usuários vejam esse conteúdo.
Opção de remoção 4: Ferramenta de remoção de URL
O nome desta ferramenta do Google é um pouco enganador, pois a forma como funciona é que oculta temporariamente o conteúdo. O Google ainda verá e rastreará esse conteúdo, mas as páginas não aparecerão para os usuários. Esse efeito temporário dura seis meses no Google, enquanto o Bing tem uma ferramenta semelhante que dura três meses. Essas ferramentas devem ser usadas nos casos mais extremos para problemas de segurança, vazamentos de dados, informações de identificação pessoal (PII) etc. Para o Google, use a Ferramenta de remoção e para o Bing, veja como bloquear URLs .
Você ainda precisa aplicar outro método junto com o uso da ferramenta de remoção para realmente remover as páginas por um período mais longo (noindex ou excluir) ou impedir que os usuários acessem o conteúdo se ainda tiverem os links (excluir ou restringir o acesso). Isso apenas oferece uma maneira mais rápida de ocultar as páginas enquanto a remoção tem tempo para ser processada. A solicitação pode levar até um dia para ser processada.
Opção de remoção 5: canonização
Quando você tem várias versões de uma página e deseja consolidar sinais como links para uma única versão, o que você deseja fazer é alguma forma de canonização . Isso é principalmente para evitar conteúdo duplicado enquanto consolida várias versões de uma página em um único URL indexado.
Você tem várias opções de canonização:
- Marca canônica . Isso especifica outro URL como a versão canônica ou a versão que você deseja mostrar. Se as páginas forem duplicadas ou muito semelhantes, tudo bem. Quando as páginas são muito diferentes, o canônico pode ser ignorado, pois é uma dica e não uma diretiva.
- Redirecionamentos . Um redirecionamento leva um usuário e um bot de pesquisa de uma página para outra. 301 é o redirecionamento mais usado pelos SEOs e informa aos mecanismos de pesquisa que você deseja que o URL final seja aquele mostrado nos resultados da pesquisa e onde os sinais são consolidados. Um redirecionamento 302 ou temporário informa aos mecanismos de pesquisa que você deseja que o URL original permaneça no índice e consolide os sinais lá.
- Manipulação de parâmetros de URL (obsoleto no início de 2022 e não é mais útil). Um parâmetro é anexado ao final da URL e normalmente inclui um ponto de interrogação, como ahrefs.com?this=parameter. Essa ferramenta do Google costumava permitir que você dissesse a eles como tratar URLs com parâmetros específicos. Por exemplo, você costumava especificar se o parâmetro alterava o conteúdo da página ou se era usado apenas para rastrear o uso.
Se você tiver várias páginas para remover do índice do Google, elas devem ser priorizadas de acordo.
Prioridade mais alta: essas páginas geralmente são relacionadas à segurança ou relacionadas a dados confidenciais. Isso inclui conteúdo que contém dados pessoais (PII), dados do cliente ou informações proprietárias.
Prioridade média: geralmente envolve conteúdo destinado a um grupo específico de usuários. Intranets da empresa ou portais de funcionários, conteúdo destinado apenas a membros e ambientes de preparação, teste ou desenvolvimento.
Baixa prioridade: essas páginas geralmente envolvem algum tipo de conteúdo duplicado . Alguns exemplos disso incluem páginas servidas de vários URLs, URLs com parâmetros e, novamente, podem incluir ambientes de preparação, teste ou desenvolvimento.
Quero abordar algumas das maneiras pelas quais geralmente vejo remoções feitas incorretamente e o que acontece em cada cenário para ajudar as pessoas a entender por que elas não funcionam.
Noindex em robots.txt
Embora o Google costumava oferecer suporte não oficial ao noindex em robots.txt, ele nunca foi um padrão oficial e agora removeu formalmente o suporte . Muitos dos sites que estavam fazendo isso estavam fazendo isso incorretamente e prejudicando a si mesmos.
Bloqueio de rastreamento em robots.txt
Rastreamento não é a mesma coisa que indexação. Mesmo que o Google esteja impedido de rastrear páginas, se houver links internos ou externos para uma página, eles ainda poderão indexá-la. O Google não saberá o que está na página porque não irá rastreá-la, mas eles sabem que existe uma página e até escreverão um título para mostrar nos resultados da pesquisa com base em sinais como o texto âncora dos links para a página .
Não siga
Isso geralmente é confundido com noindex, e algumas pessoas o usarão no nível da página, esperando que a página não seja indexada. Nofollow é uma dica e, embora originalmente impedisse o rastreamento de links na página e links individuais com o atributo nofollow, esse não é mais o caso. O Google agora pode rastrear esses links se quiser. Nofollow também foi usado em links individuais para tentar impedir que o Google rastejasse para páginas específicas e para escultura de PageRank. Novamente, isso não funciona mais, pois nofollow é uma dica. No passado, se a página tivesse outro link para ela, o Google ainda poderia descobrir a partir desse caminho de rastreamento alternativo.
Observe que você pode encontrar páginas nofollowed em massa usando este filtro no Gerenciador de páginas no Ahrefs’ Site Audit .
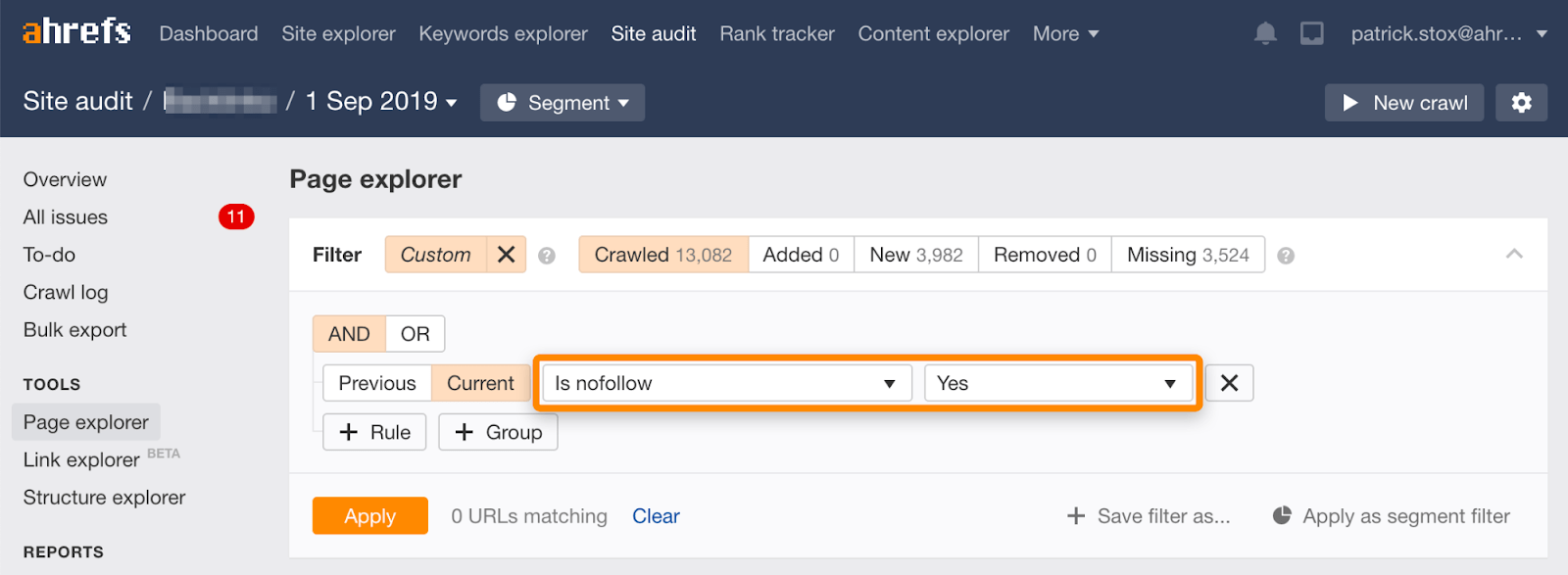
Como raramente faz sentido não seguir todos os links em uma página, o número de resultados deve ser zero ou próximo de zero. Se houver resultados correspondentes, peço que verifique se a diretiva nofollow foi adicionada acidentalmente no lugar de noindex e escolha um método de remoção mais apropriado, se necessário.
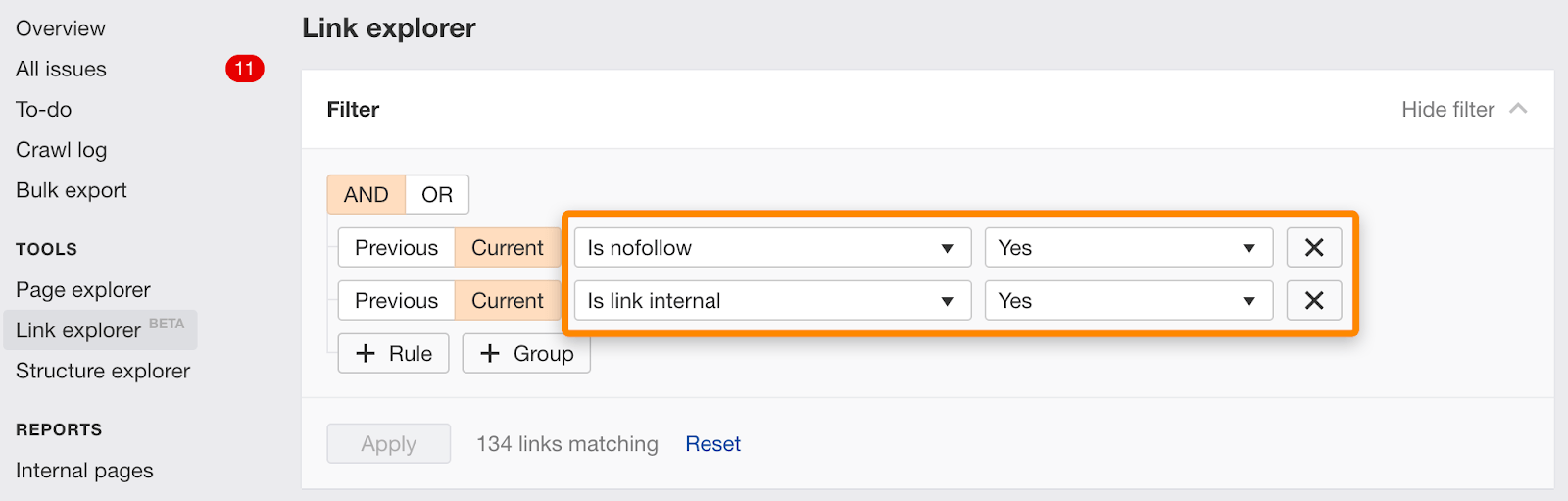
Você também pode encontrar links individuais marcados como nofollow usando este filtro no Link Explorer.
Noindex e canônico para outro URL
Esses sinais são conflitantes. Noindex diz para remover a página do índice e canonical diz que outra página é a versão que deve ser indexada. Isso pode realmente funcionar para consolidação, pois o Google normalmente optará por ignorar o noindex e, em vez disso, usar o canônico como o sinal principal. No entanto, este não é um comportamento absoluto. Há um algoritmo envolvido e existe o risco de que a tag noindex possa ser o sinal contado. Se for esse o caso, as páginas não serão consolidadas corretamente.
Observe que você pode encontrar páginas não indexadas com canônicos não autorreferenciais usando este conjunto de filtros no Gerenciador de páginas em Auditoria do site:
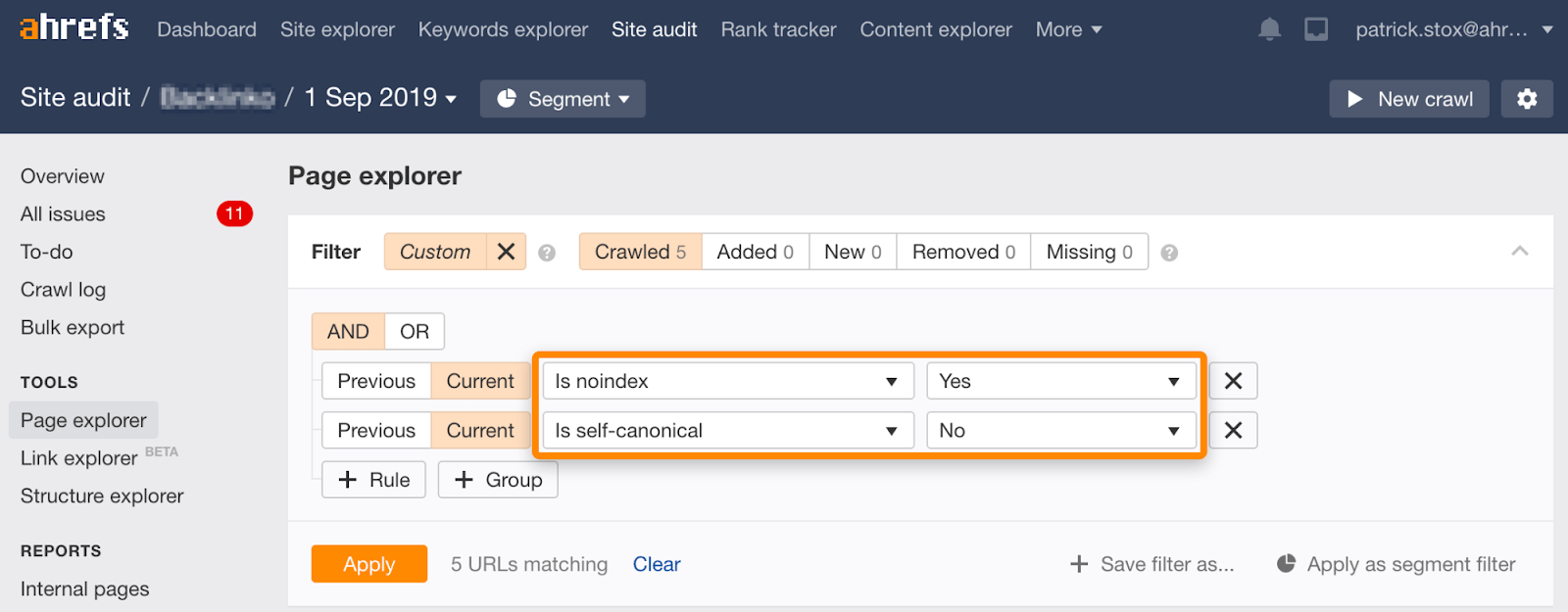
Noindex, aguarde o rastreamento do Google e bloqueie o rastreamento
Existem algumas maneiras pelas quais isso geralmente acontece:
- As páginas já estão bloqueadas, mas são indexadas, as pessoas adicionam noindex e desbloqueiam para que o Google possa rastrear e ver o noindex e, em seguida, bloquear o rastreamento das páginas novamente.
- As pessoas adicionam tags noindex para as páginas que desejam remover e, depois que o Google rastreia e processa a tag noindex, elas bloqueiam o rastreamento das páginas.
De qualquer maneira, o estado final é impedido de rastrear. Se você se lembra, falamos anteriormente sobre como o rastreamento não é o mesmo que a indexação. Mesmo que essas páginas estejam bloqueadas, elas ainda podem acabar no índice.
Se você for o proprietário do conteúdo que está sendo usado em outro site, poderá registrar uma reclamação com base na Lei de Direitos Autorais do Milênio Digital (DMCA). Você pode usar a ferramenta de remoção de direitos autorais do Google para fazer o que é chamado de remoção DMCA, que solicita a remoção de qualquer material protegido por direitos autorais.
E se for um conteúdo sobre você, mas não em um site de sua propriedade?
Se você estiver na UE, poderá remover conteúdo que contenha informações sobre você, graças a uma ordem judicial pelo direito de ser esquecido. Você pode solicitar a remoção de informações pessoais usando o formulário de remoção de privacidade da UE .
Para remover imagens do Google, a maneira mais fácil é com o robots.txt. Embora o suporte não oficial para remoção de páginas tenha sido removido do robots.txt como mencionamos anteriormente, simplesmente não permitir o rastreamento de imagens é a maneira correta de remover imagens.
Para uma única imagem:
User-agent: Googlebot-Image Não permitir: /images/dogs.jpg
Para todas as imagens:
User-agent: Googlebot-Image Não permitir: /
Pensamentos finais
Como você remove URLs é bastante situacional. Falamos sobre várias opções, mas se ainda estiver confuso sobre qual é a certa para você, consulte o fluxograma no início.