{kind=link}
A maioria dos sites usa algum tipo de JavaScript para adicionar interatividade e melhorar a experiência do usuário. Alguns o usam para menus, obtendo produtos ou preços, obtendo conteúdo de várias fontes ou, em alguns casos, para tudo no site. A realidade da web atual é que o JavaScript é onipresente.
Como disse John Mueller , do Google :
Não estou dizendo que os SEOs precisam aprender a programar JavaScript. É exatamente o oposto. Os SEOs precisam principalmente saber como o Google lida com JavaScript e como solucionar problemas. Em muito poucos casos, um SEO terá permissão para tocar no código. Meu objetivo com este post é ajudá-lo a aprender:
- O que é Javascript SEO
- Como o Google processa páginas com JavaScript
- Como testar e solucionar problemas de JavaScript
- Opções de renderização
- Tornando seu site JavaScript amigável para SEO

O JavaScript SEO é uma parte do SEO técnico (Search Engine Optimization) que busca tornar sites pesados em JavaScript fáceis de rastrear e indexar, bem como fáceis de pesquisar. O objetivo é fazer com que esses sites sejam encontrados e tenham uma classificação mais alta nos mecanismos de pesquisa .
O JavaScript é ruim para SEO; JavaScript é mau? De jeito nenhum. É apenas diferente do que muitos SEOs estão acostumados, e há um pouco de curva de aprendizado. As pessoas tendem a usá-lo em excesso para coisas em que provavelmente há uma solução melhor, mas às vezes você precisa trabalhar com o que tem. Apenas saiba que Javascript não é perfeito e nem sempre é a ferramenta certa para o trabalho. Ele não pode ser analisado progressivamente, ao contrário do HTML e CSS, e pode ser pesado no carregamento e no desempenho da página. Em muitos casos, você pode estar trocando desempenho por funcionalidade.
Nos primeiros dias dos mecanismos de pesquisa, uma resposta HTML baixada era suficiente para ver o conteúdo da maioria das páginas. Graças ao surgimento do JavaScript, os mecanismos de pesquisa agora precisam renderizar muitas páginas como um navegador faria para que possam ver o conteúdo como o usuário o vê.
O sistema que lida com o processo de renderização no Google é chamado de Web Rendering Service (WRS). O Google forneceu um diagrama simplista para explicar como esse processo funciona.
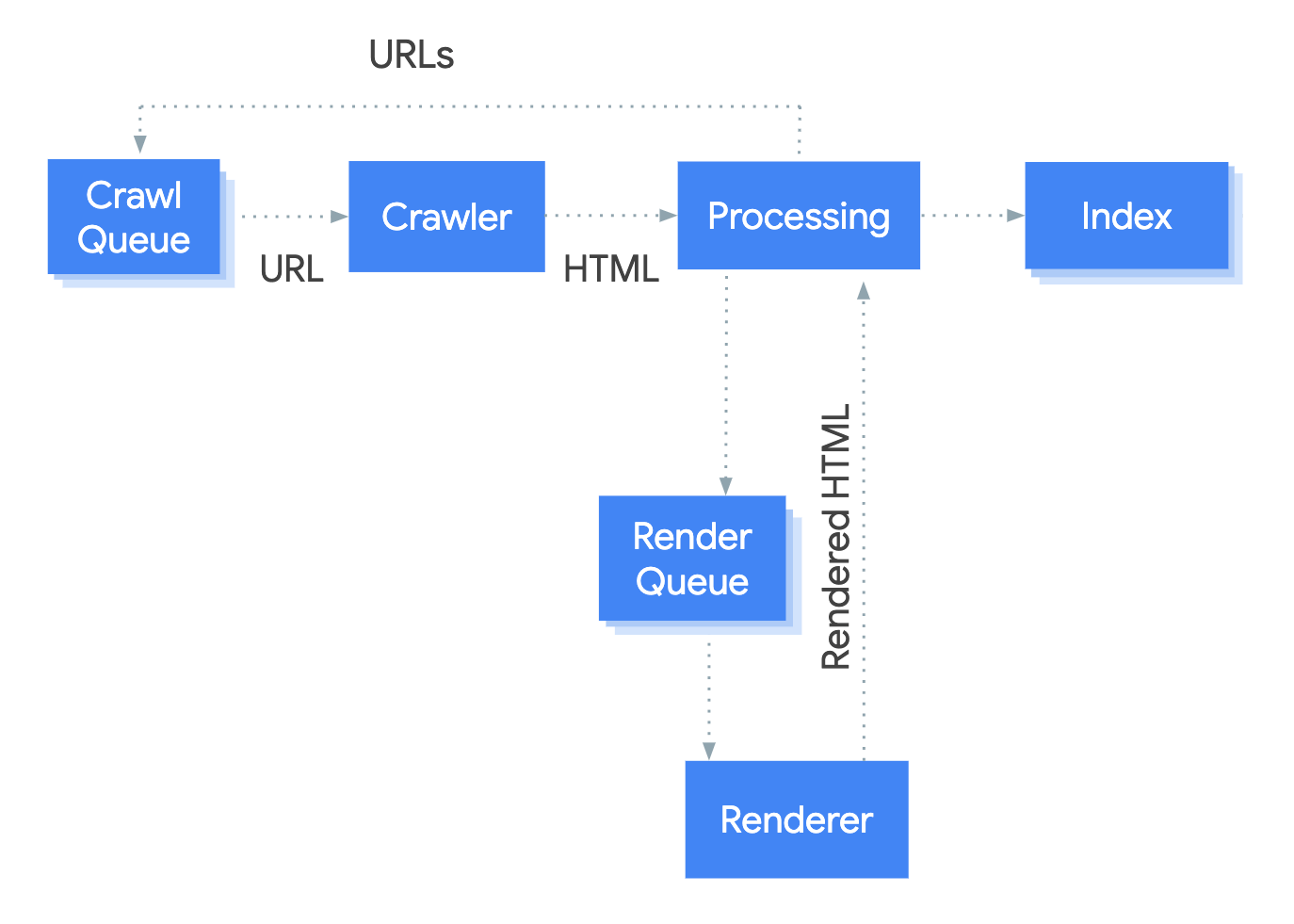
Digamos que iniciamos o processo em URL.
1. Rastreador
O rastreador envia solicitações GET ao servidor. O servidor responde com cabeçalhos e o conteúdo do arquivo, que é salvo.
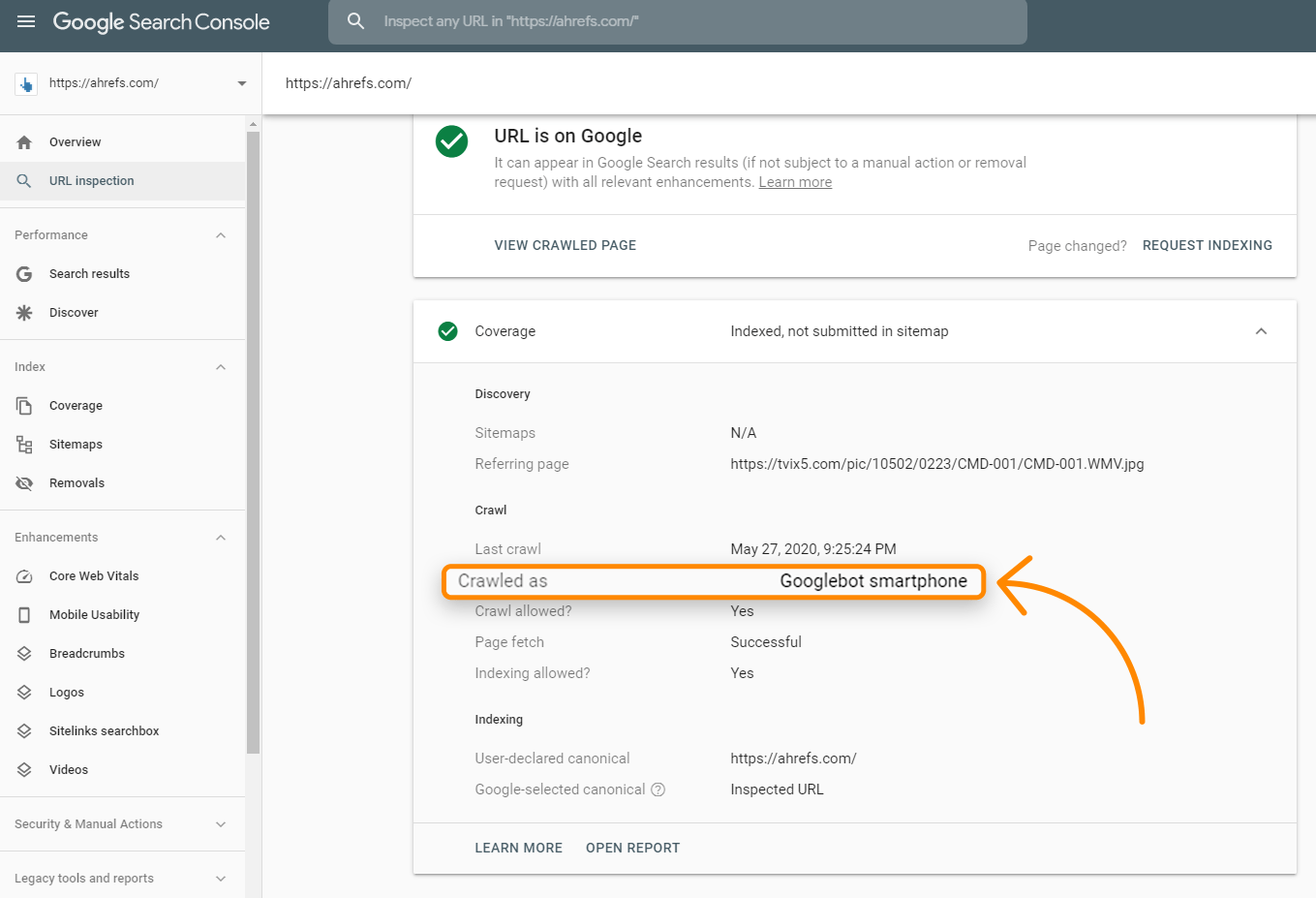
É provável que a solicitação venha de um agente de usuário móvel, já que o Google está principalmente na indexação móvel primeiro agora. Você pode verificar como o Google está rastreando seu site com a Ferramenta de inspeção de URL no Search Console . Ao executá-lo para um URL, verifique as informações de cobertura para “Rastreado como” e ele deve informar se você ainda está na indexação para desktop ou na indexação para dispositivos móveis.
As solicitações vêm principalmente de Mountain View, CA, EUA, mas também fazem algum rastreamento de páginas adaptáveis à localidade fora dos Estados Unidos. Menciono isso porque alguns sites bloqueiam ou tratam visitantes de um país específico ou que usam um determinado IP de maneiras diferentes, o que pode fazer com que seu conteúdo não seja visto pelo Googlebot .
Alguns sites também podem usar a detecção de agente do usuário para mostrar conteúdo a um rastreador específico. Especialmente com sites JavaScript, o Google pode estar vendo algo diferente de um usuário. É por isso que as ferramentas do Google, como a ferramenta de inspeção de URL dentro do Google Search Console, o teste de compatibilidade com dispositivos móveis e o teste de rich results são importantes para solucionar problemas de SEO em JavaScript. Eles mostram o que o Google vê e são úteis para verificar se o Google pode estar bloqueado e se eles podem ver o conteúdo da página. Abordarei como testar isso na seção sobre o renderizador porque existem algumas diferenças importantes entre a solicitação GET baixada, a página renderizada e até mesmo as ferramentas de teste.
Também é importante observar que, embora o Google declare a saída do processo de rastreamento como “HTML” na imagem acima, na realidade, eles estão rastreando e armazenando os recursos necessários para construir a página, como HTML, arquivos JavaScript e arquivos CSS .
2. Processamento
Existem muitos sistemas ofuscados pelo termo “Processamento” na imagem. Vou cobrir alguns deles que são relevantes para o JavaScript.
Recursos e Links
O Google não navega de página em página como um usuário faria. Parte do processamento é verificar a página em busca de links para outras páginas e arquivos necessários para construir a página. Esses links são retirados e adicionados à fila de rastreamento, que é o que o Google está usando para priorizar e agendar o rastreamento.
O Google extrairá links de recursos (CSS, JS, etc.) necessários para criar uma página a partir de coisas como <link> tags. No entanto, os links para outras páginas precisam estar em um formato específico para que o Google os trate como links. Os links internos e externos precisam ser uma <a> tag com um href atributo. Há muitas maneiras de fazer isso funcionar para usuários com JavaScript que não são fáceis de pesquisar.
Bom:
<a href="/page">simples é bom</a> <a href=”/page” onclick=”goTo('page')”>ainda bem</a>
Ruim:
<a onclick=”goTo('page')”>não, não href</a> <a href=”javascript:goTo('page')”>não, link ausente</a> <a href=”javascript:void(0)”>não, link perdido</a> <span onclick=”goTo('page')”>não é o elemento HTML correto</span> <option value="page">não, elemento HTML errado</option> <a href="#">sem link</a> Button, ng-click, existem muitas outras maneiras de fazer isso incorretamente.
Também vale a pena notar que os links internos adicionados com JavaScript não serão selecionados até a renderização. Isso deve ser relativamente rápido e não é motivo de preocupação na maioria dos casos.
Cache
Todos os arquivos baixados pelo Google, incluindo páginas HTML, arquivos JavaScript, arquivos CSS, etc., serão armazenados em cache de forma agressiva. O Google ignorará os tempos do seu cache e buscará uma nova cópia quando quiser. Falarei um pouco mais sobre isso e por que é importante na seção Renderizador.
eliminação duplicada
O conteúdo duplicado pode ser eliminado ou despriorizado do HTML baixado antes de ser enviado para renderização. Com modelos de shell de aplicativo, muito pouco conteúdo e código podem ser mostrados na resposta HTML. Na verdade, todas as páginas do site podem exibir o mesmo código, e esse pode ser o mesmo código exibido em vários sites. Às vezes, isso pode fazer com que as páginas sejam tratadas como duplicatas e não sejam processadas imediatamente. Pior ainda, a página errada ou até mesmo o site errado pode aparecer nos resultados da pesquisa. Isso deve se resolver com o tempo, mas pode ser problemático, especialmente com sites mais novos.
Diretivas mais restritivas
O Google escolherá as declarações mais restritivas entre HTML e a versão renderizada de uma página. Se o JavaScript alterar uma instrução e isso entrar em conflito com a instrução do HTML, o Google simplesmente obedecerá o que for mais restritivo. Noindex substituirá index e noindex em HTML ignorará totalmente a renderização.
3. Fila de renderização
Cada página vai para o renderizador agora. Uma das maiores preocupações de muitos SEOs com JavaScript e indexação em dois estágios (HTML, em seguida, página renderizada) é que as páginas podem não ser renderizadas por dias ou até semanas. Quando o Google investigou isso, descobriu que as páginas foram para o renderizador em um tempo médio de 5 segundos e o 90º percentil foi de minutos. Portanto, a quantidade de tempo entre obter o HTML e renderizar as páginas não deve ser uma preocupação na maioria dos casos.
4. Renderizador
O renderizador é onde o Google renderiza uma página para ver o que o usuário vê. É aqui que eles processarão o JavaScript e quaisquer alterações feitas pelo JavaScript no Document Object Model (DOM) .
Para isso, o Google está usando um navegador Chrome sem cabeça que agora é “evergreen”, o que significa que deve usar a versão mais recente do Chrome e oferecer suporte aos recursos mais recentes. Até recentemente, o Google estava renderizando com o Chrome 41, então muitos recursos não eram suportados.
O Google tem mais informações sobre o Web Rendering Service (WRS) , que inclui coisas como negar permissões, ficar sem estado, achatar DOM de luz e DOM de sombra e muito mais que vale a pena ler.
A renderização em escala da Web pode ser a 8ª maravilha do mundo. É um empreendimento sério e exige uma quantidade enorme de recursos. Por causa da escala, o Google está usando muitos atalhos com o processo de renderização para acelerar as coisas. Na Ahrefs, somos a única grande ferramenta de SEO que renderiza páginas da Web em escala e conseguimos renderizar cerca de 150 milhões de páginas por dia para tornar nosso índice de links mais completo. Ele nos permite verificar redirecionamentos de JavaScript e também podemos mostrar links que encontramos inseridos com JavaScript que mostramos com uma tag JS nos relatórios de link:

Recursos em cache
O Google está confiando fortemente em recursos de cache. As páginas são armazenadas em cache; os arquivos são armazenados em cache; basicamente, tudo é armazenado em cache antes de ser enviado ao renderizador. Eles não estão saindo e baixando cada recurso para cada carregamento de página, mas usando recursos em cache para acelerar esse processo.
Isso pode levar a alguns estados impossíveis em que as versões anteriores do arquivo são usadas no processo de renderização e a versão indexada de uma página pode conter partes de arquivos mais antigos. Você pode usar o controle de versão de arquivo ou impressão digital de conteúdo para gerar novos nomes de arquivo quando forem feitas alterações significativas para que o Google tenha que baixar a versão atualizada do recurso para renderização.
Sem tempo limite fixo
Um mito comum de SEO é que o renderizador espera apenas cinco segundos para carregar sua página. Embora seja sempre uma boa ideia tornar seu site mais rápido , esse mito realmente não faz sentido com a maneira como o Google armazena em cache os arquivos mencionados acima. Eles estão basicamente carregando uma página com tudo já armazenado em cache. O mito vem das ferramentas de teste, como a Ferramenta de Inspeção de URL, onde os recursos são buscados ao vivo e precisam definir um limite razoável.
Não há tempo limite fixo para o renderizador. O que eles provavelmente estão fazendo é algo semelhante ao que o Rendertron público faz. Eles provavelmente esperam por algo como networkidle0, onde não está ocorrendo mais nenhuma atividade de rede e também definem uma quantidade máxima de tempo no caso de algo travar ou alguém tentar minerar bitcoin em suas páginas.
O que o Googlebot vê
O Googlebot não realiza ações em páginas da web. Eles não vão clicar nas coisas ou rolar, mas isso não significa que eles não tenham soluções alternativas. Para o conteúdo, desde que seja carregado no DOM sem uma ação necessária, eles o verão. Abordarei mais isso na seção de solução de problemas, mas basicamente, se o conteúdo estiver no DOM, mas apenas oculto, ele será visto. Se não for carregado no DOM até depois de um clique, o conteúdo não será encontrado.
O Google também não precisa rolar para ver seu conteúdo porque eles têm uma solução inteligente para ver o conteúdo. Para dispositivos móveis, eles carregam a página com um tamanho de tela de 411 x 731 pixels e redimensionam o comprimento para 12.140 pixels . Essencialmente, torna-se um telefone muito longo com um tamanho de tela de 411×12140 pixels. Para desktop, eles fazem o mesmo e vão de 1024×768 pixels para 1024×9307 pixels.

Outro atalho interessante é que o Google não pinta os pixels durante o processo de renderização. Leva tempo e recursos adicionais para concluir o carregamento de uma página, e eles realmente não precisam ver o estado final com os pixels pintados. Eles só precisam conhecer a estrutura e o layout e conseguem isso sem precisar pintar os pixels. Como Martin Splitt, do Google, coloca:
Na pesquisa do Google, não nos importamos muito com os pixels porque não queremos realmente mostrá-los a alguém. Queremos processar as informações e as informações semânticas, então precisamos de algo no estado intermediário. Não precisamos realmente pintar os pixels.
Um visual pode ajudar a explicar um pouco melhor o que foi cortado. Nas ferramentas de desenvolvimento do Chrome, se você executar um teste na guia Desempenho, obterá um gráfico de carregamento. A parte verde sólida aqui representa o estágio de pintura e para o Googlebot isso nunca acontece, então eles economizam recursos.

Cinza = downloads
Azul = HTML
Amarelo = JavaScript
Roxo = Layout
Verde = Pintura
5. Fila de rastreamento
O Google tem um recurso que fala um pouco sobre crawl budget , mas você deve saber que cada site tem seu próprio crawl budget , e cada requisição tem que ser priorizada. O Google também precisa equilibrar o rastreamento do seu site em relação a todos os outros sites da Internet. Sites mais novos em geral ou sites com muitas páginas dinâmicas provavelmente serão rastreados mais lentamente. Algumas páginas serão atualizadas com menos frequência do que outras e alguns recursos também podem ser solicitados com menos frequência.
Uma ‘pegadinha’ com sites JavaScript é que eles podem atualizar apenas partes do DOM. Navegar para outra página como usuário pode não atualizar alguns aspectos, como tags de título ou tags canônicas no DOM, mas isso pode não ser um problema para os mecanismos de pesquisa. Lembre-se, o Google carrega cada página sem estado, então eles não estão salvando informações anteriores e não estão navegando entre as páginas. Já vi SEOs tropeçarem pensando que há um problema por causa do que eles veem depois de navegar de uma página para outra, como uma tag canônica que não é atualizada, mas o Google pode nunca ver esse estado. Os desenvolvedores podem corrigir isso atualizando o estado usando o que é chamado de API de histórico, mas, novamente, pode não ser um problema. Atualize a página e veja o que você vê ou, melhor ainda, execute-a em uma das ferramentas de teste do Google para ver o que eles veem. Mais sobre isso em um segundo.
Exibir código-fonte x inspecionar
Ao clicar com o botão direito do mouse em uma janela do navegador, você verá algumas opções para visualizar o código-fonte da página e para inspecioná-la. View-source mostrará a você o mesmo que uma solicitação GET mostraria. Este é o HTML bruto da página. Inspecionar mostra o DOM processado após as alterações serem feitas e está mais próximo do conteúdo que o Googlebot vê. É basicamente a versão atualizada e mais recente da página. Você deve usar inspecionar a origem da exibição ao trabalhar com JavaScript.
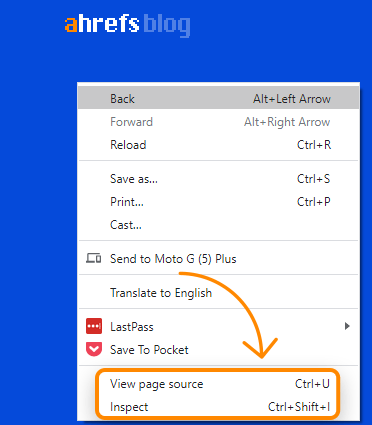
Você precisa definir um user-agent personalizado com o Chrome DevTools para solucionar problemas de sites que pré-renderizam com base em user-agents específicos.
Cache do Google
O cache do Google não é uma maneira confiável de verificar o que o Googlebot vê. Geralmente é o HTML inicial, embora às vezes seja o HTML renderizado ou uma versão mais antiga. O sistema foi feito para ver o conteúdo quando um site está fora do ar. Não é particularmente útil como ferramenta de depuração.
Ferramentas de teste do Google
As ferramentas de teste do Google, como o URL Inspector dentro do Google Search Console, Mobile Friendly Tester, Rich Results Tester são úteis para depuração. Ainda assim, mesmo essas ferramentas são um pouco diferentes do que o Google verá. Já falei sobre o tempo limite de cinco segundos nessas ferramentas que o renderizador não tem, mas essas ferramentas também diferem porque extraem recursos em tempo real e não usam as versões em cache como o renderizador faria. As capturas de tela nessas ferramentas também mostram páginas com os pixels pintados, que o Google não vê no renderizador.
As ferramentas são úteis para ver se o conteúdo é carregado por DOM. O HTML mostrado nessas ferramentas é o DOM renderizado. Você pode procurar um trecho de texto para ver se ele foi carregado por padrão.
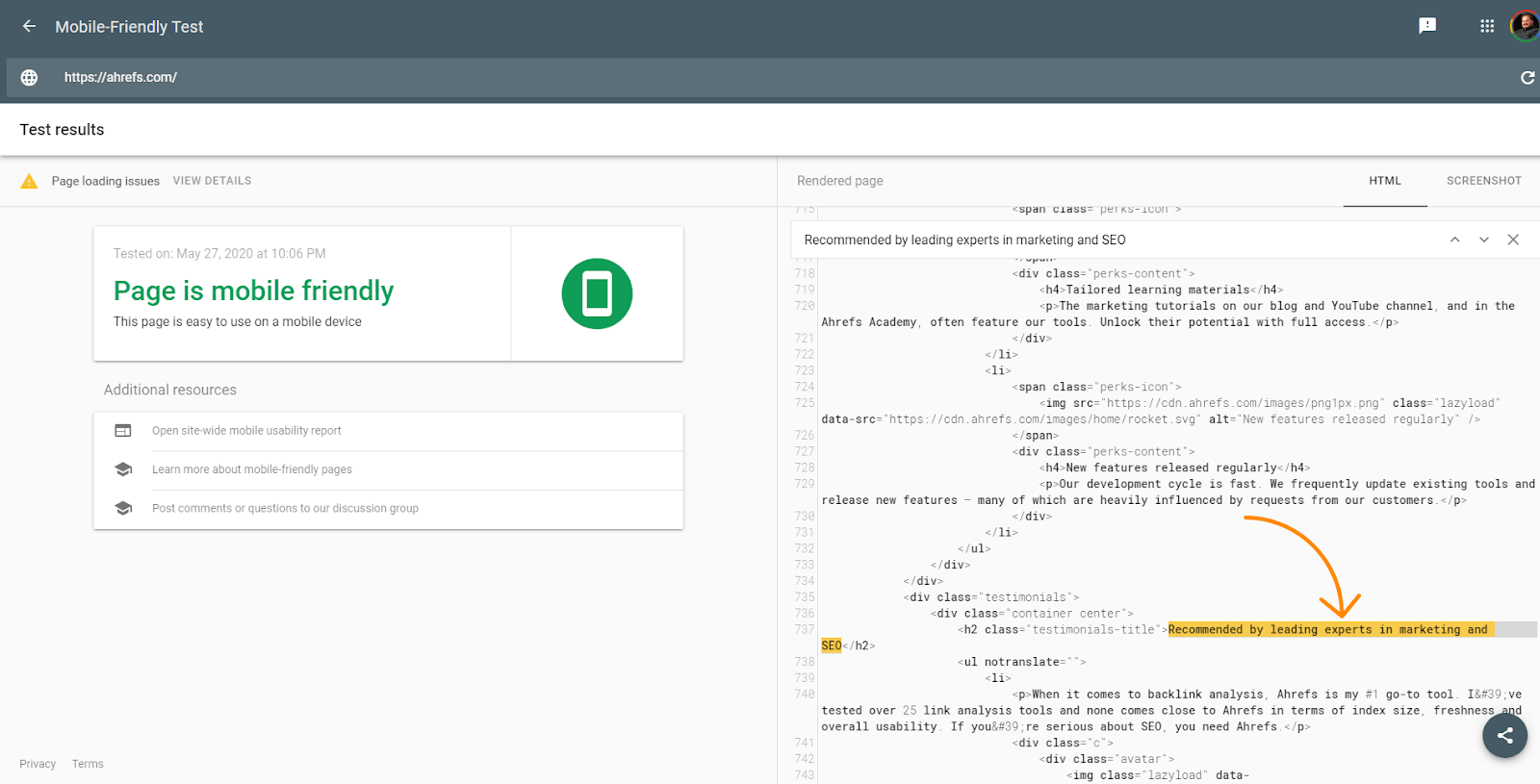
As ferramentas também mostrarão recursos que podem estar bloqueados e mensagens de erro do console que são úteis para depuração.
Pesquisando texto no Google
Muitos sites JavaScript podem não estar mostrando todo o conteúdo para o Google. Uma verificação rápida que você pode fazer é simplesmente procurar um trecho do seu conteúdo no Google.
Procure por “alguma frase do seu conteúdo” e veja se a página é retornada. Se for, seu conteúdo provavelmente foi visto. Observe que o conteúdo oculto por padrão pode não aparecer em seu snippet nas SERPs .
Ahrefs
Juntamente com as páginas de renderização de índice de link, você pode ativar o JavaScript nos rastreamentos de auditoria do site para desbloquear mais dados em suas auditorias. Fornecemos o HTML bruto e renderizado para cada página e você pode pesquisar no conteúdo de qualquer uma delas.
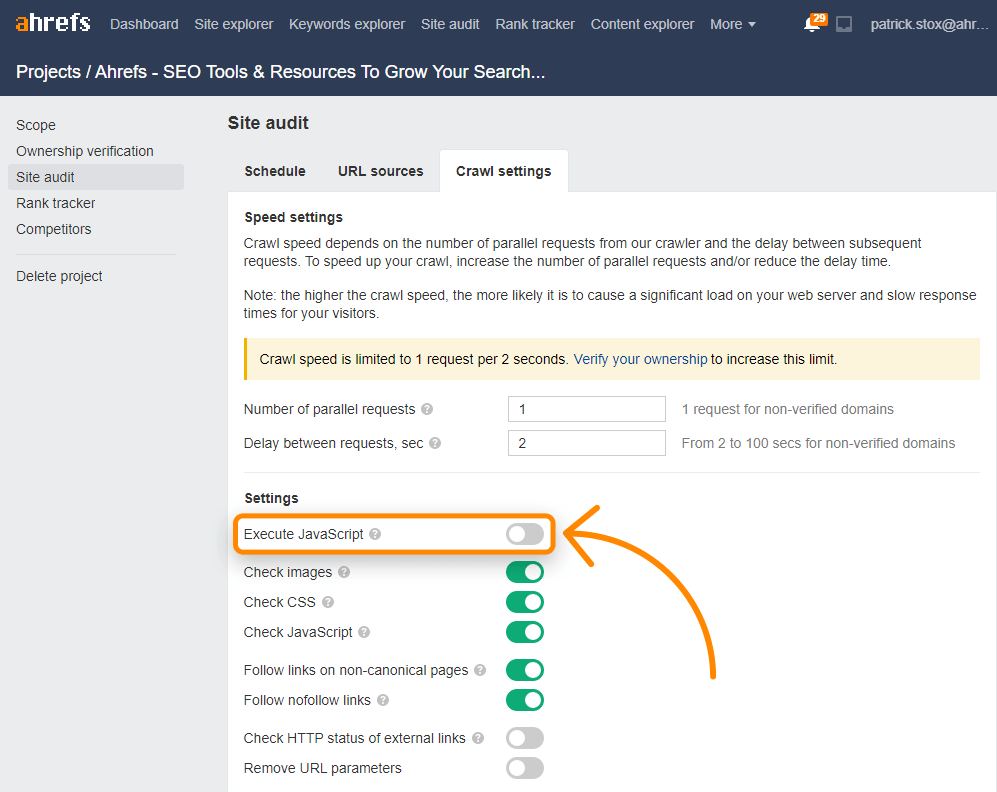
A barra de ferramentas Ahrefs também oferece suporte a JavaScript e permite comparar HTML com versões renderizadas de tags.
Existem muitas opções quando se trata de renderizar JavaScript. O Google tem um gráfico sólido que vou mostrar. Qualquer tipo de configuração de SSR, renderização estática e pré-renderização será adequada para os mecanismos de pesquisa. O principal que causa problemas é a renderização completa do lado do cliente, onde toda a renderização ocorre no navegador.
Embora o Google provavelmente esteja bem mesmo com a renderização do lado do cliente, é melhor escolher uma opção de renderização diferente para dar suporte a outros mecanismos de pesquisa . O Bing também tem suporte para renderização de JavaScript , mas a escala é desconhecida. Yandex e Baidu têm suporte limitado pelo que vi, e muitos outros mecanismos de pesquisa têm pouco ou nenhum suporte para JavaScript.

Há também a opção de Dynamic Rendering , que é renderização para determinados agentes de usuário. Isso é basicamente uma solução alternativa, mas pode ser útil para renderizar certos bots, como mecanismos de pesquisa ou até mesmo bots de mídia social. Os bots de mídia social não executam JavaScript, então coisas como tags OG não serão vistas a menos que você renderize o conteúdo antes de entregá-lo a eles.
Se você estava usando o antigo esquema de rastreamento AJAX , observe que ele foi obsoleto e pode não ser mais compatível.
Muitos dos processos são semelhantes às coisas que os SEOs já estão acostumados a ver, mas pode haver pequenas diferenças.
SEO na página
Todas as regras normais de SEO na página para conteúdo, tags de título , meta descrições , atributos alternativos , meta tags de robô , etc. ainda se aplicam. Consulte SEO na página: um guia prático .
Marcação padrão e tags de substituição
Em muitos casos, os desenvolvedores de JavaScript definem valores padrão no HTML bruto para elementos como <title> e tags como <canonical> e meta descrições. Eles geralmente são substituídos pelo HTML renderizado, mas os bots podem ver ambos.
No caso de títulos e descrições, o Google simplesmente substituirá o valor e isso não será um problema. Para tags canônicas, se eles virem 2 valores diferentes, eles os tratarão como se nenhum canônico tivesse sido definido.
Outro elemento frequentemente esquecido é que os atributos alt nas imagens raramente são definidos.
Permitir rastreamento
Não bloqueie o acesso aos recursos. O Google precisa ser capaz de acessar e baixar recursos para que eles possam renderizar as páginas adequadamente. Em seu robots.txt , a maneira mais fácil de permitir que os recursos necessários sejam rastreados é adicionar:
User-Agent: Googlebot Permitir: .js Permitir: .css
Verifique também os arquivos robots.txt para quaisquer subdomínios ou domínios adicionais dos quais você possa estar fazendo solicitações, como aqueles para suas chamadas de API.
URLs
Altere os URLs ao atualizar o conteúdo. Já mencionei a API de histórico, mas você deve saber que, com as estruturas JavaScript, elas terão um roteador que permite mapear para URLs limpas . Você não deseja usar hashes (#) para roteamento. Isso é especialmente um problema para o Vue e algumas das versões anteriores do Angular. Portanto, para uma URL como abc.com/#something, qualquer coisa após um # é normalmente ignorada por um servidor. Para corrigir isso no Vue, você pode trabalhar com seu desenvolvedor para alterar o seguinte:
Visualização do roteador: Use o modo 'Histórico' em vez do modo 'Hash' tradicional. roteador const = novo VueRouter ({ modo: 'histórico', roteador: [] //a matriz de links do roteador )}
conteúdo duplicado
Com JavaScript, pode haver vários URLs para o mesmo conteúdo, o que leva a problemas de conteúdo duplicado. Isso pode ser causado por letras maiúsculas, IDs, parâmetros com IDs, etc. Então, tudo isso pode existir:
domain.com/Abc
domain.com/abc
domain.com/123
domain.com/?id=123
A solução é simples. Escolha uma versão que deseja indexar e defina tags canônicas .
Opções de tipo de “plugin” de SEO
Para frameworks JavaScript, eles geralmente são chamados de módulos. Você encontrará versões para muitos dos frameworks populares como React, Vue e Angular procurando pelo nome do framework + módulo como “React Helmet”. Meta tags, Helmet e Head são todos módulos populares com funcionalidade semelhante, permitindo que você defina muitas das tags populares necessárias para SEO.
páginas de erro
Como os frameworks JavaScript não são do lado do servidor, eles não podem gerar um erro de servidor como um 404. Você tem algumas opções diferentes para páginas de erro:
- Use um redirecionamento de JavaScript para uma página que responda com um código de status 404
- Adicione uma tag noindex à página que está falhando junto com algum tipo de mensagem de erro como “404 Página não encontrada”. Isso será tratado como um soft 404, pois o código de status real retornado será um 200 ok.
Mapa do site
As estruturas JavaScript geralmente têm roteadores que mapeiam para URLs limpas. Esses roteadores geralmente possuem um módulo adicional que também pode criar mapas do site. Você pode encontrá-los pesquisando o mapa do site do seu sistema + roteador, como “Vue router sitemap”. Muitas das soluções de renderização também podem ter opções de mapa do site. Novamente, basta encontrar o sistema que você usa e pesquisar no Google o sistema + mapa do site, como “Gatsby sitemap” e você certamente encontrará uma solução que já existe.
Redirecionamentos
Os SEOs são usados para redirecionamentos 301/302 , que são do lado do servidor. Mas o Javascript normalmente é executado no lado do cliente. Tudo bem, pois o Google processa a página conforme o redirecionamento. Os redirecionamentos ainda passam todos os sinais como PageRank . Geralmente, você pode encontrar esses redirecionamentos no código procurando por “window.location.href”.
Internacionalização
Geralmente existem algumas opções de módulos para diferentes frameworks que suportam alguns recursos necessários para internacionalização como hreflang . Eles geralmente são portados para diferentes sistemas e incluem i18n, intl ou, muitas vezes, os mesmos módulos usados para tags de cabeçalho como Helmet podem ser usados para adicionar tags necessárias.
Carregamento lento
Geralmente existem módulos para lidar com o carregamento lento . Se você ainda não percebeu, existem módulos para lidar com praticamente tudo que você precisa fazer ao trabalhar com frameworks JavaScript. Lazy e Suspense são os módulos mais populares para carregamento lento. Você vai querer carregar imagens lentamente, mas tenha cuidado para não carregar conteúdo lentamente. Isso pode ser feito com JavaScript, mas pode significar que não foi detectado corretamente pelos mecanismos de pesquisa.